Audio Classification using Machine Learning
EuroPython 2019, Basel
Audio Mixtures
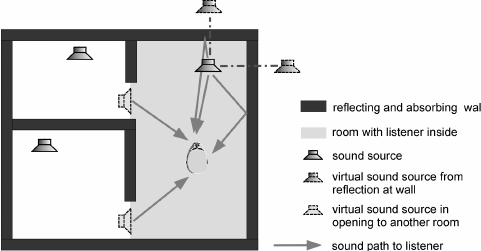
Audio acquisition

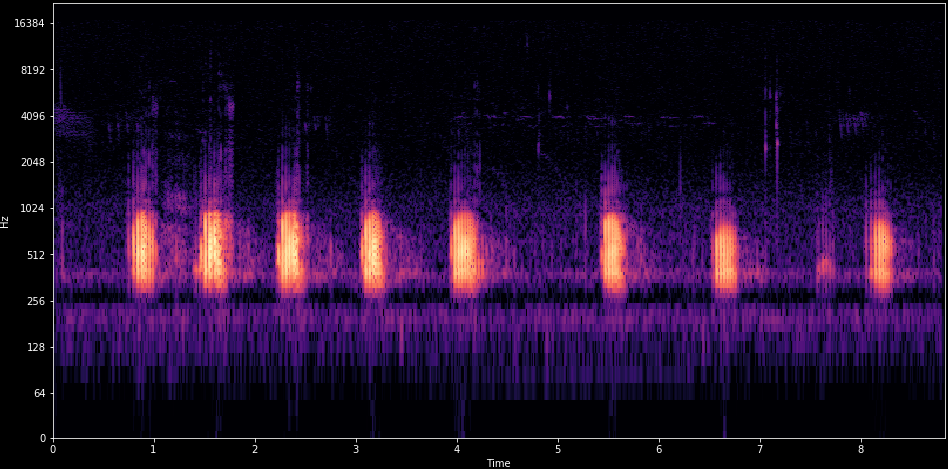
Spectrogram
Computed using Short-Time-Fourier-Transform (STFT)
Urbansound8k
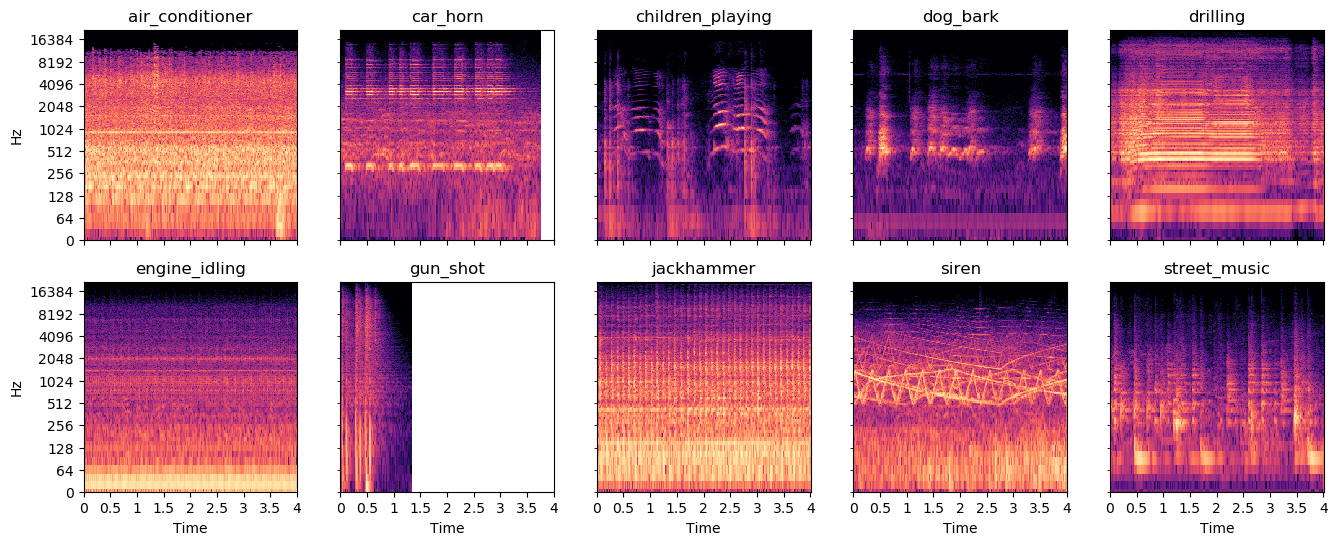
State-of-the-art accuracy: 79% - 82%
Pipeline

Analysis windows

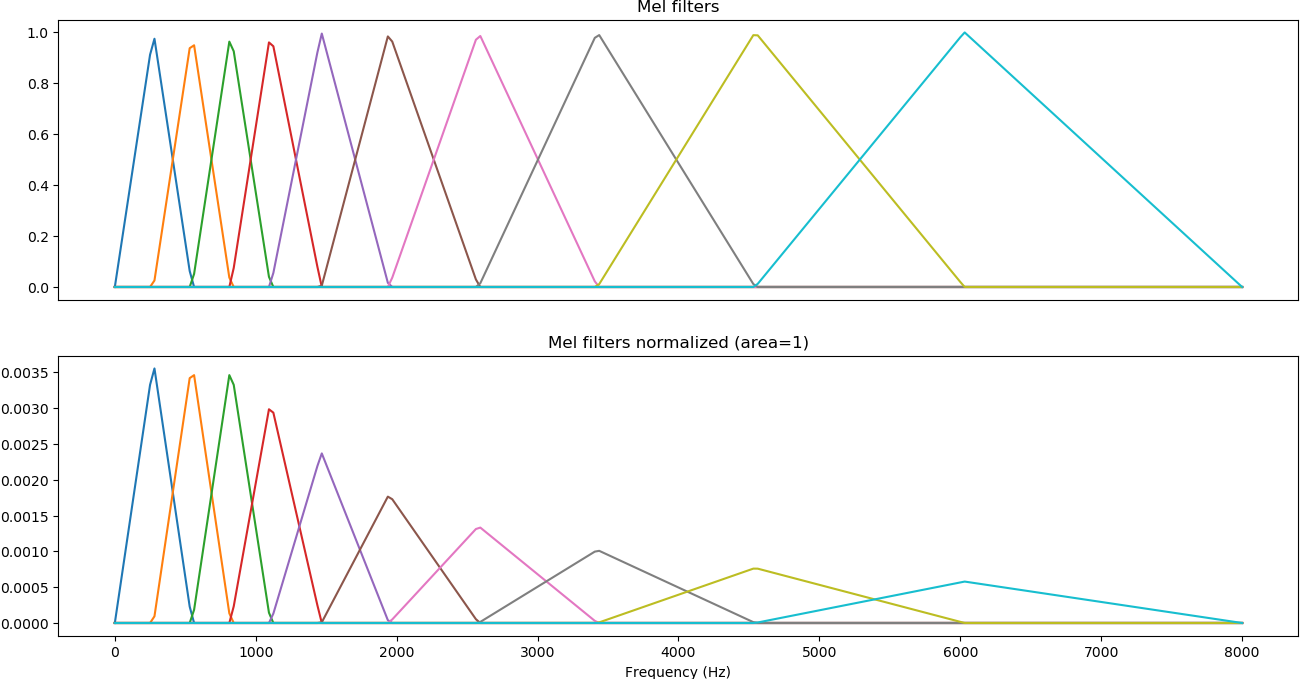
Mel-filters
Normalization
- log-scale compression
- Subtract mean
- Standard scale

SB-CNN

Environmental Sound Classification on Microcontrollers using Convolutional Neural Networks

Data Augmentation
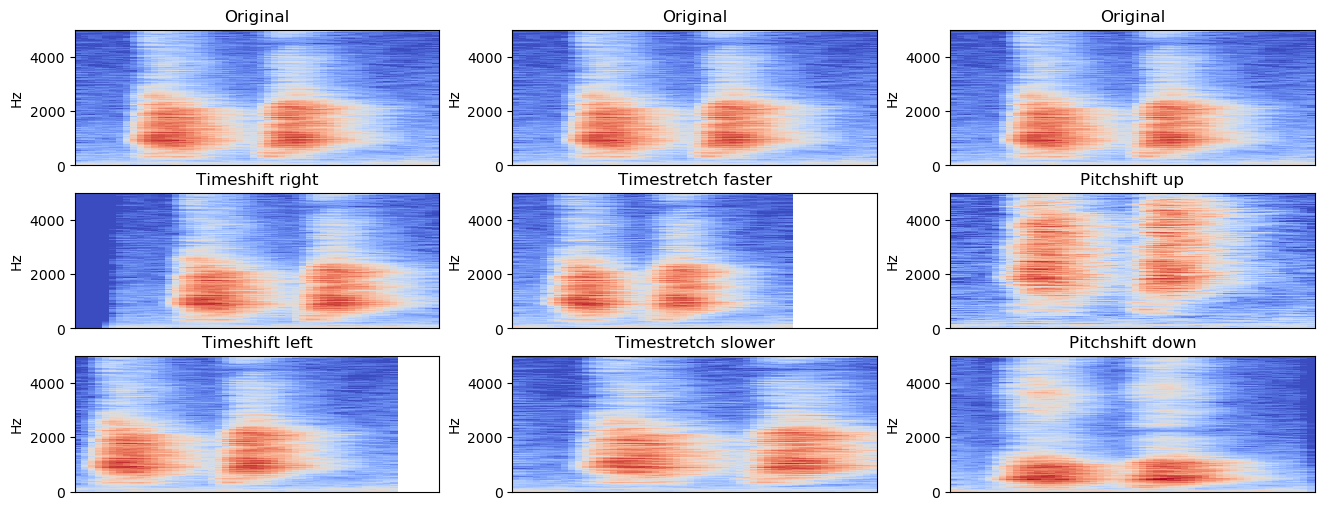
- Adding noise. Random/sampled
- Mixup: Mixing two samples
Annotating audio
