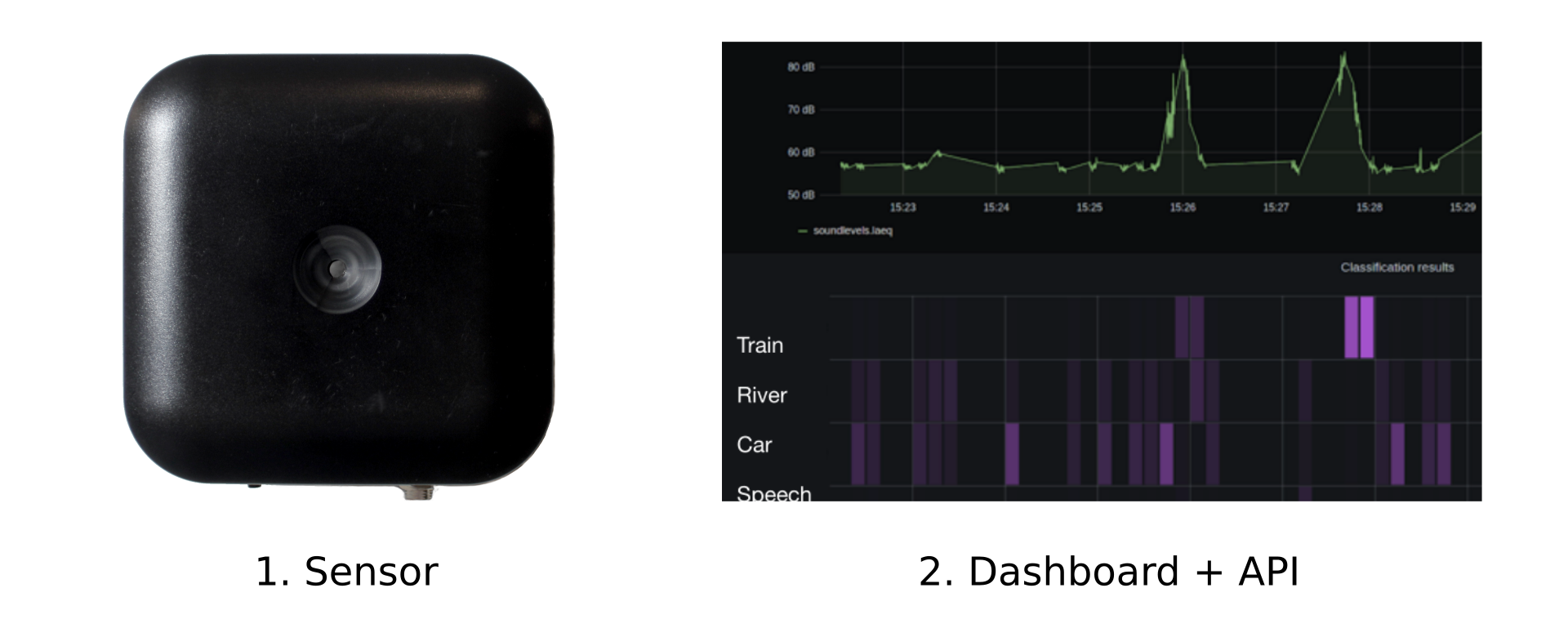
About Soundsensing
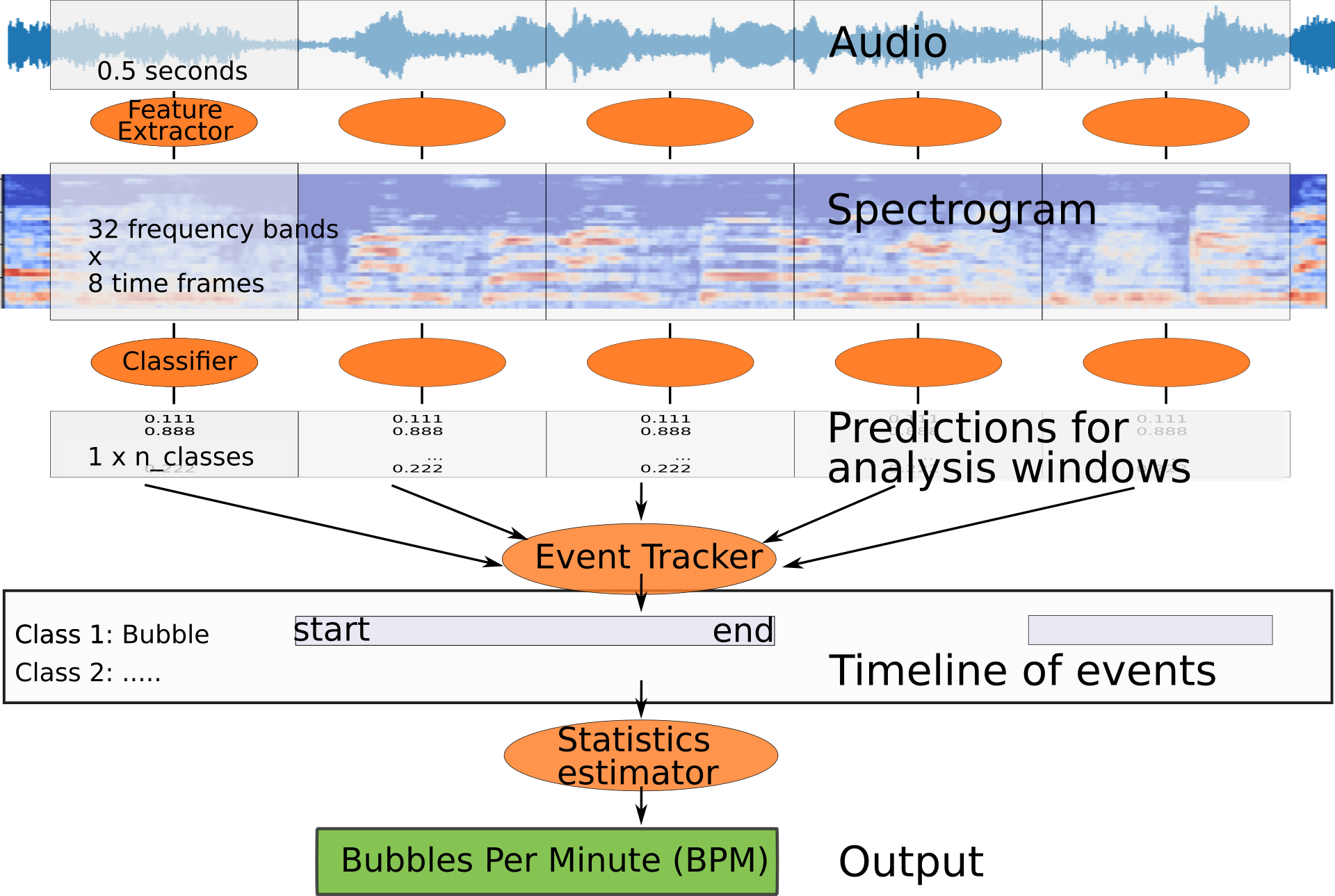
Sound Event Detection
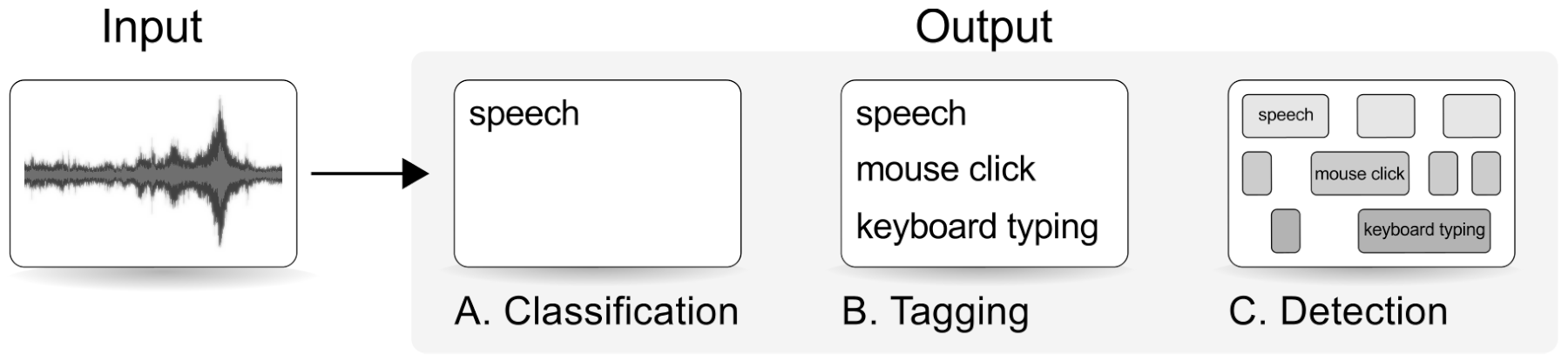
Given input audio return the timestamps (start, end) for each event class
Alcohol is produced via fermentation

Fermentation tracking
Fermentation activity can be tracked as Bubbles Per Minute (BPM).
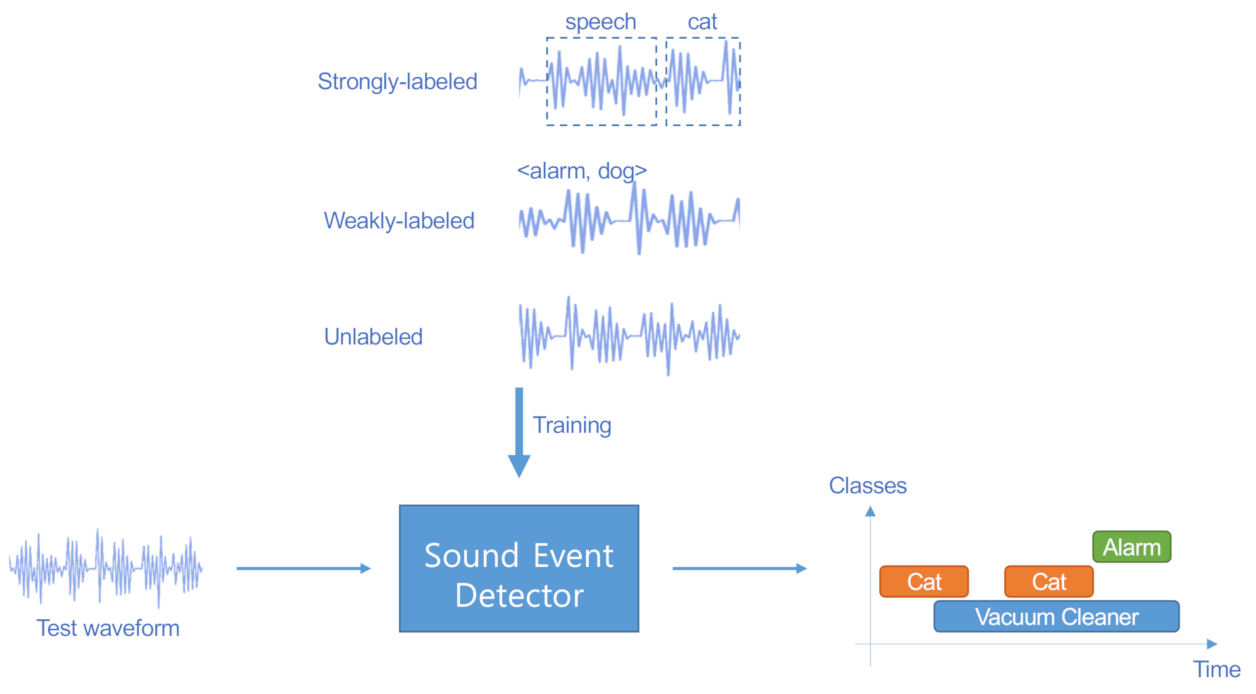
Supervised Machine Learning
Labeling data manually using Audacity

import pandas
labels = pandas.read_csv(path, sep='\t', header=None,
names=['start', 'end', 'annotation'],
dtype=dict(start=float,end=float,annotation=str))Audio ML pipeline overview
Spectrogram
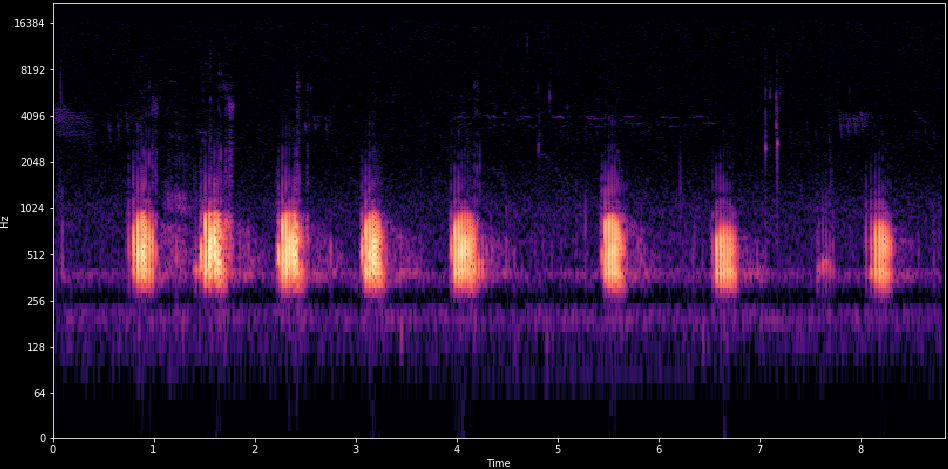
import librosa
audio, sr = librosa.load(path)
spec = librosa.feature.melspectrogram(y=audio, sr=sr)
spec_db = librosa.power_to_db(spec, ref=np.max)
lr.display.specshow(ps_db, x_axis='time', y_axis='mel')CNN classifier model
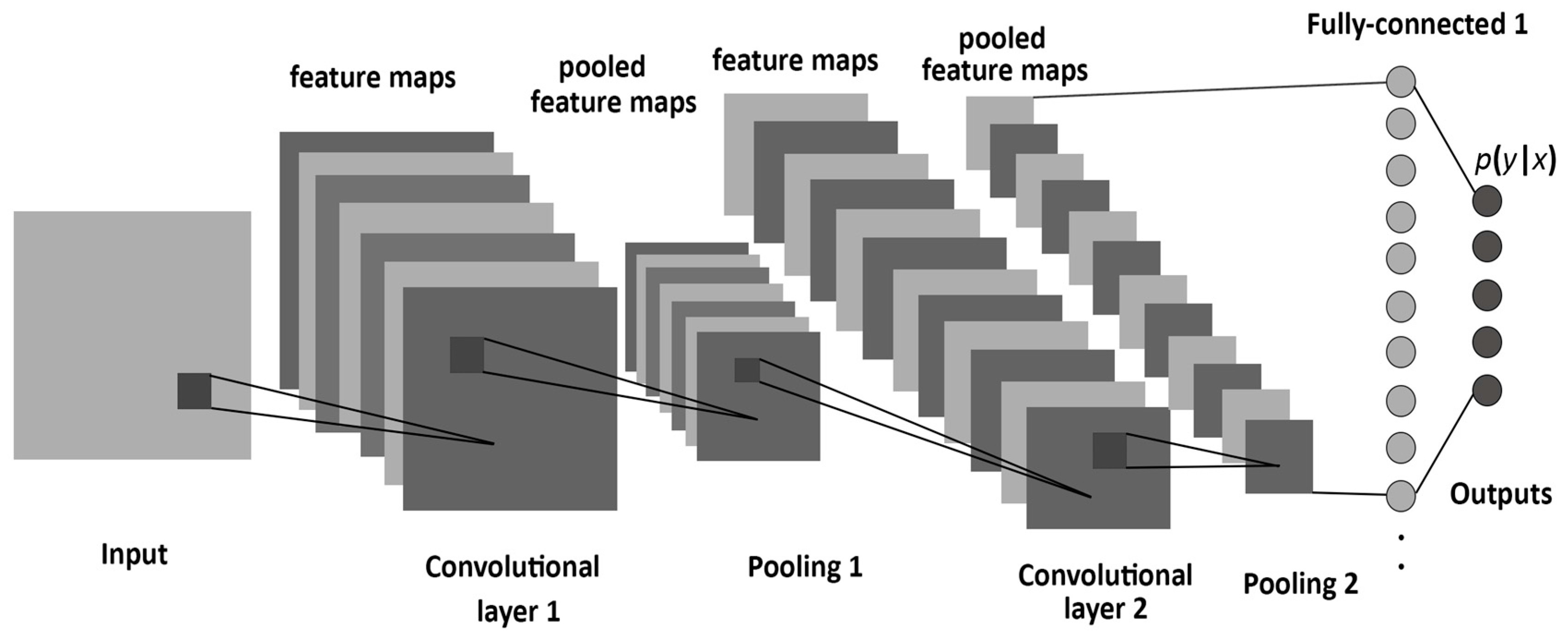
from tensorflow import keras
from keras.layers import Convolution2D, MaxPooling2D
model = keras.Sequential([
Convolution2D(filters, kernel,
input_shape=(bands, frames, channels)),
MaxPooling2D(pool_size=pool),
....
])Evaluation
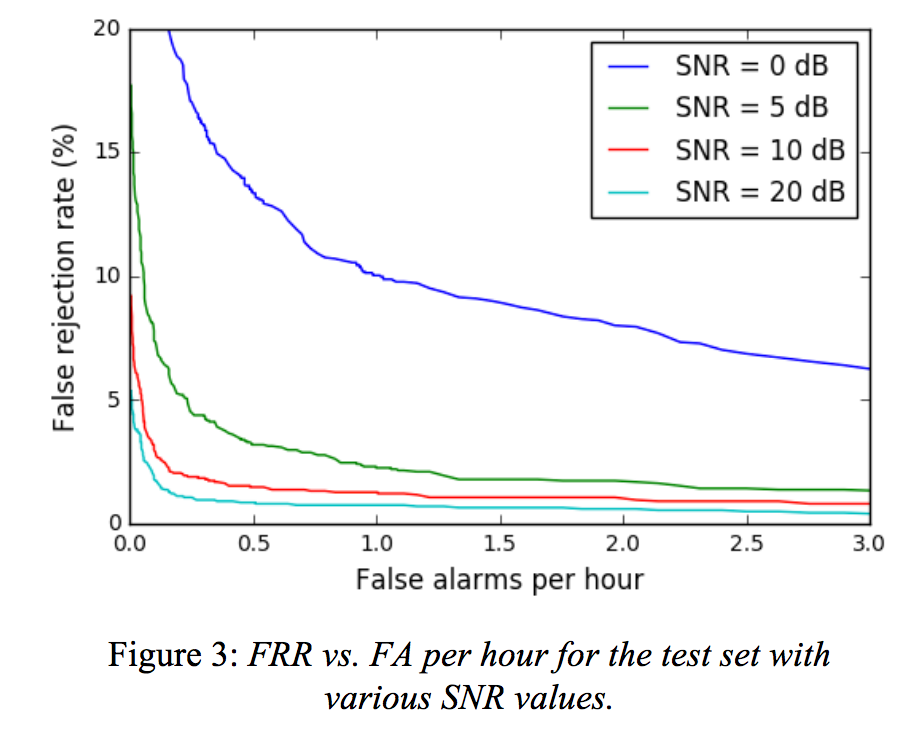
Statistics Estimator
To compute the Bubbles Per Minute
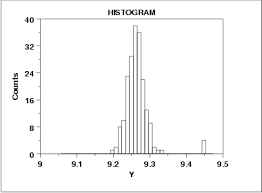
- Using the typical time-between-events
- Assumes regularity
- Median more robust against outliers
Tracking over time using Brewfather
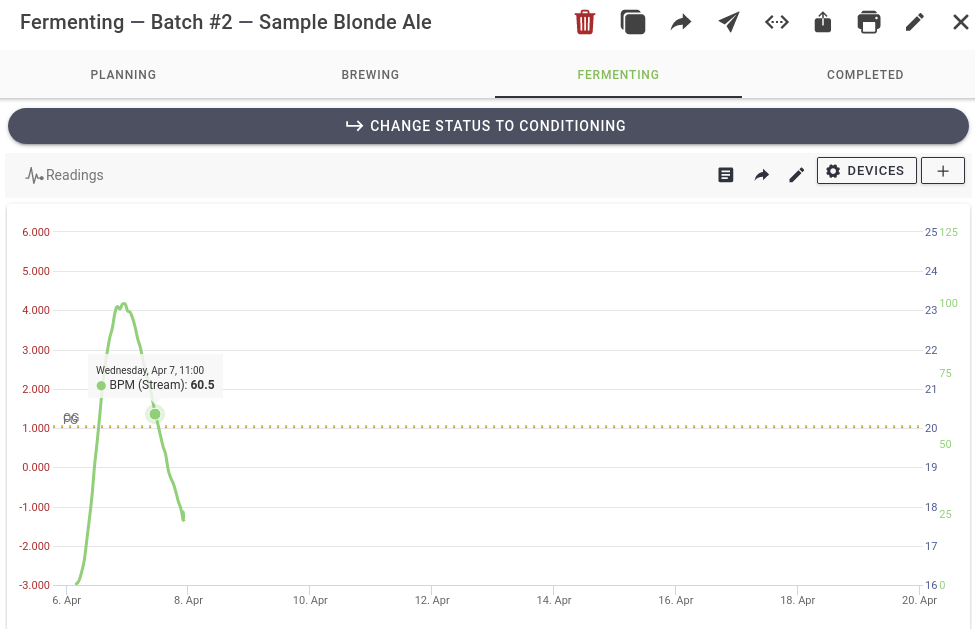
# API documentation: https://docs.brewfather.app/integrations/custom-stream
import requests
url = 'http://log.brewfather.net/stream?id=9MmXXXXXXXXX'
data = dict(name='brewaed-0001', bpm=CALCULATED-BPM)
r = requests.post(url, json=data)Continious Monitoring using Audio ML
Want to deploy Continious Monitoring with Audio? Consider using the Soundsensing sensors and data-platform.
Get in Touch! contact@soundsensing.no
Semi-automatic labelling
Using a Gaussian Mixture, Hidden Markov Model (GMM-HMM)
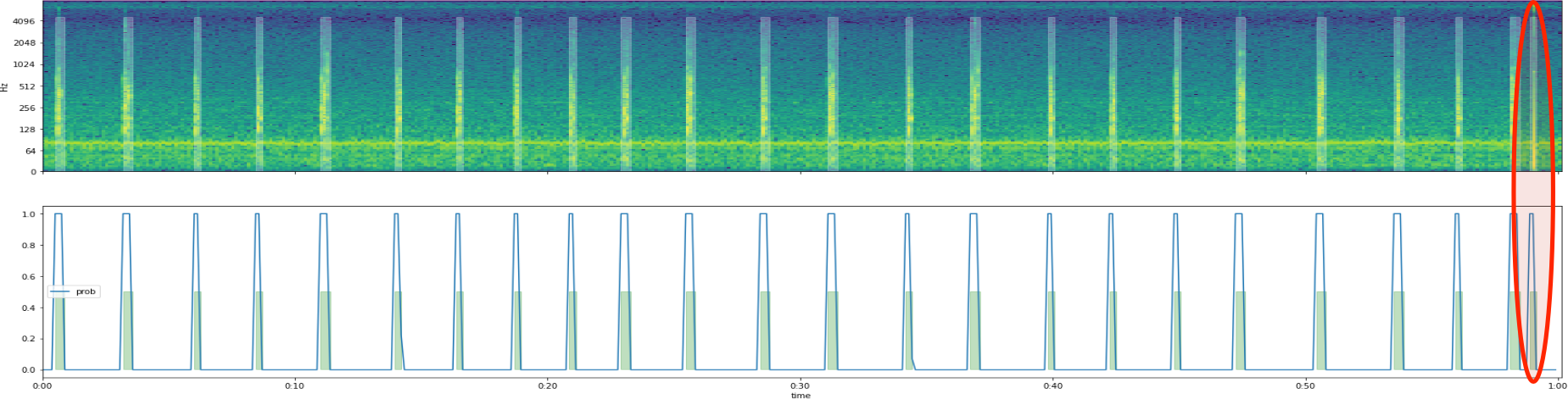
import hmmlearn.hmm, librosa, sklearn.preprocessing
features = librosa.feature.mfcc(audio, n_mfcc=13, ...)
model = hmmlearn.hmm.GMMHMM(n_components=2, ...)
X = sklearn.preprocessing.StandardScaler().fit_transform(data)
model.fit(X)
probabilities = model.score_samples(X)[1][:,1]Analysis windows
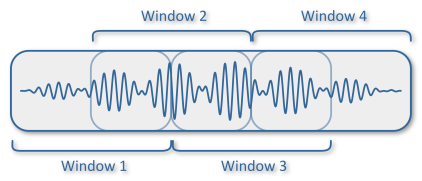
Window length bit longer than the event length.
Overlapping gives classifier multiple chances at seeing each event.
Reducing overlap increases resolution! Overlap for AES: 10%