Recognizing sounds with Machine Learning and Python
PyCode 2019, Gdansk
Soundsensing

Supervised Learning

Learning process

Urbansound8k
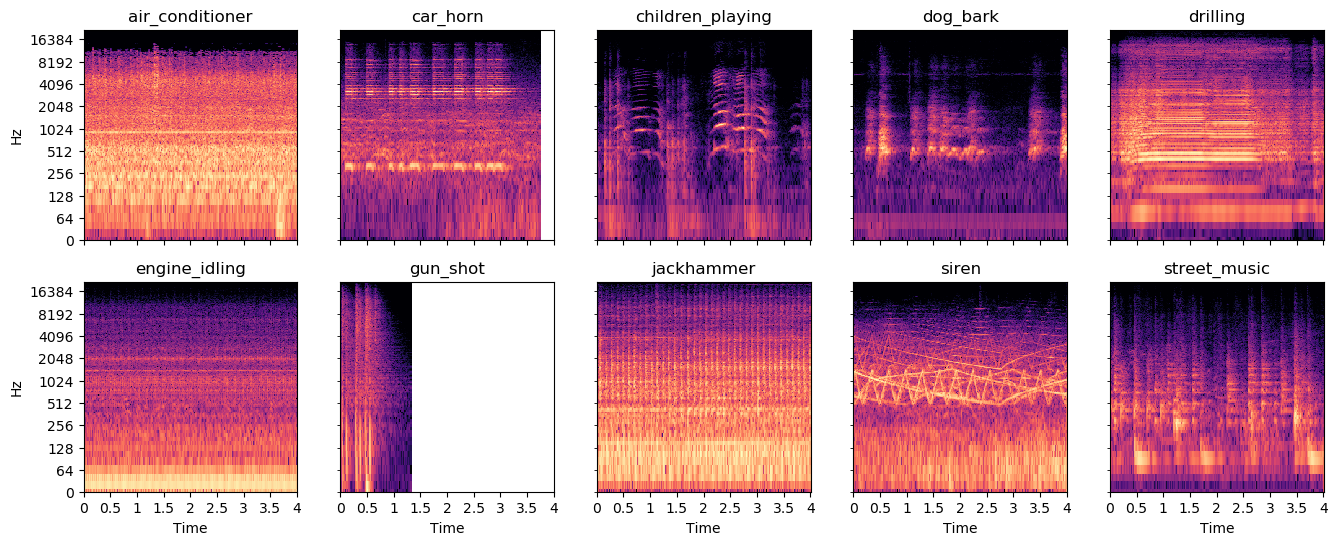
State-of-the-art accuracy: 79% - 82%
Audio Mixtures
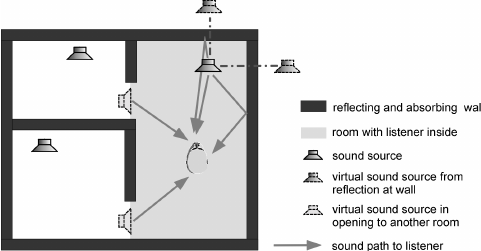
Audio acquisition

Spectrogram

Pipeline

Convolutional Neural Network
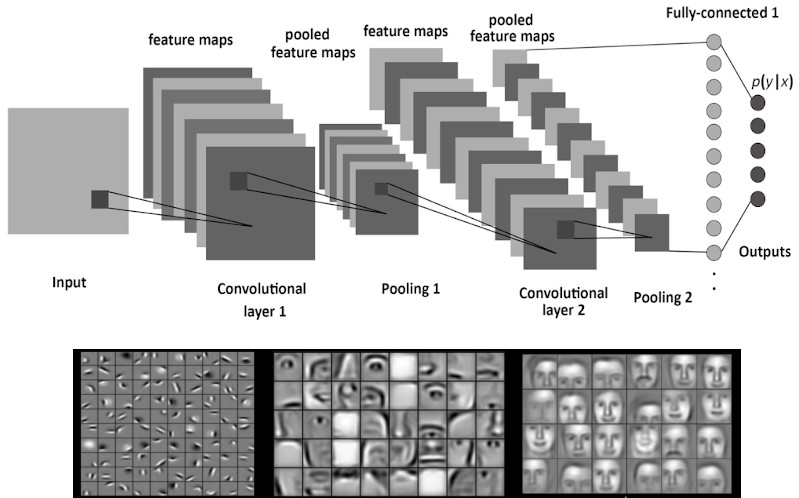
Img: Data Science Central, Albelwi2017
SB-CNN

Data Augmentation
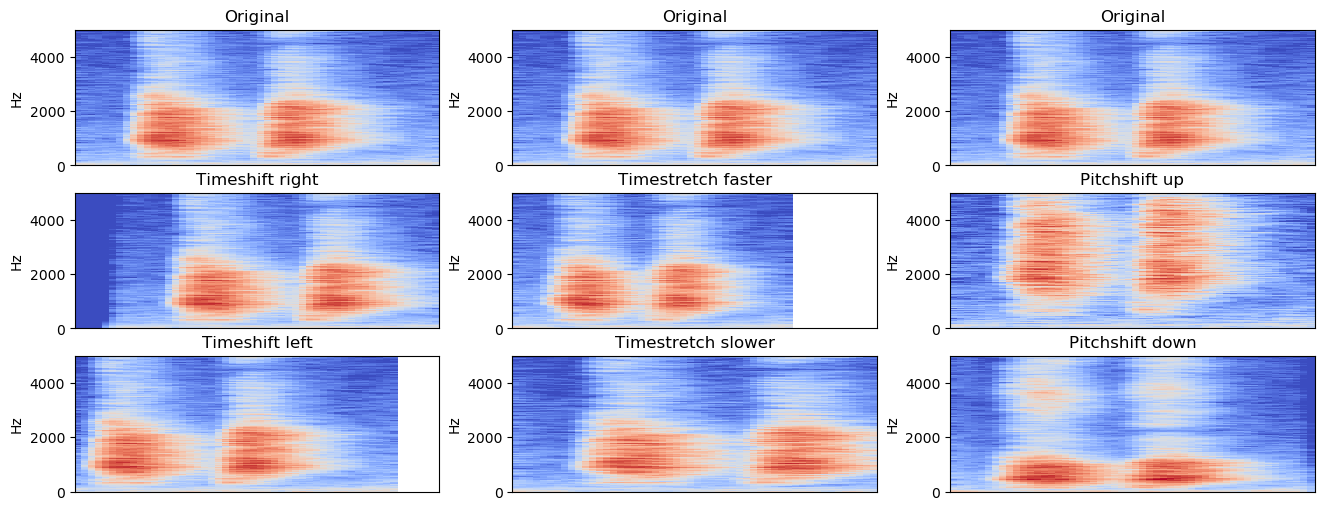
- Adding noise. Random/sampled
Mixup. Mixing two samples, adjusting class labelsSpecAugment. Mask spectrogram sections to augment
Transfer Learning from images
![]()
Annotating audio

Thesis
Environmental Sound Classification on Microcontrollers using Convolutional Neural Networks

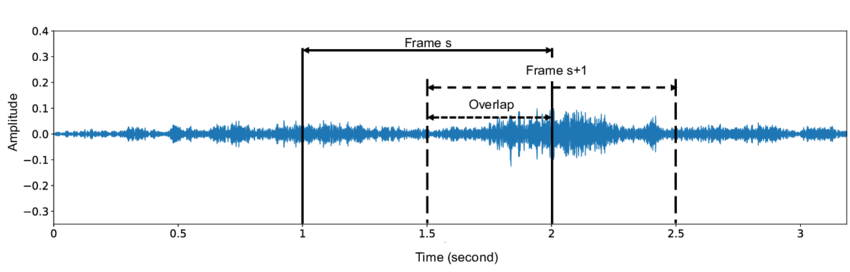
Analysis windows
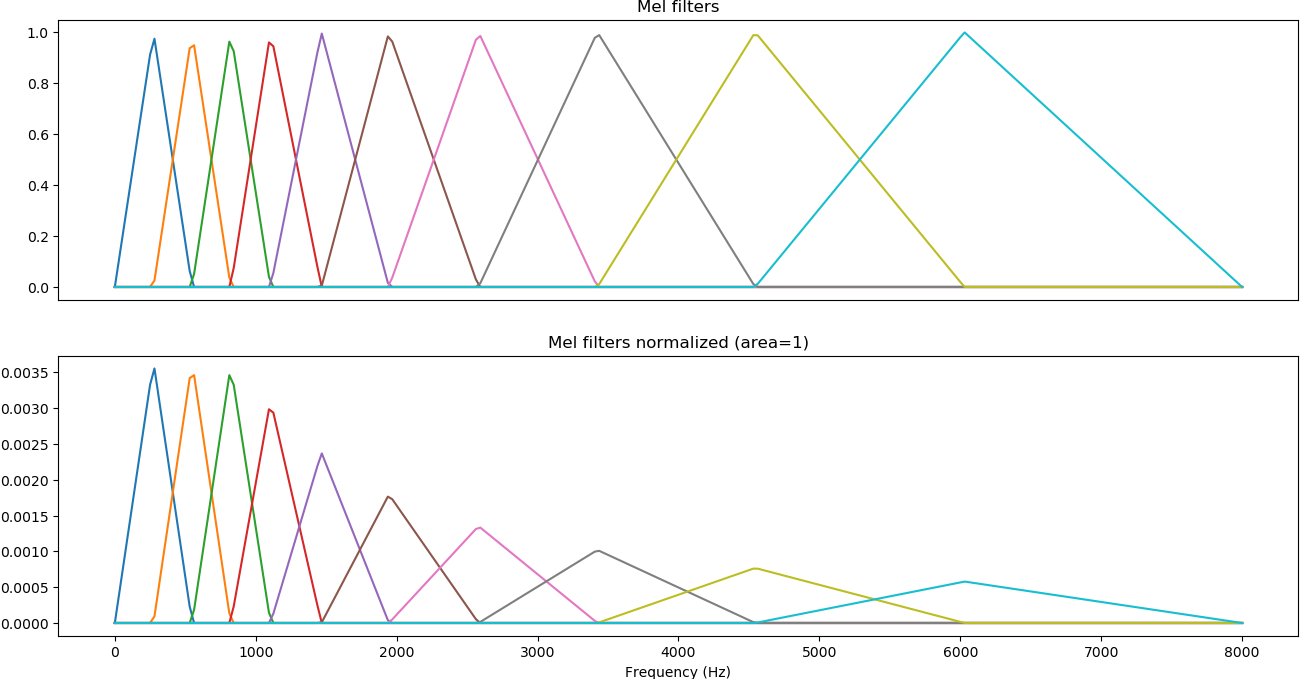
Mel-filters
Spectrogram normalization
- log-scale compression
- Subtract mean
- Standard scale
