Classification of Environmental Sound using IoT sensors
November 19, 2019
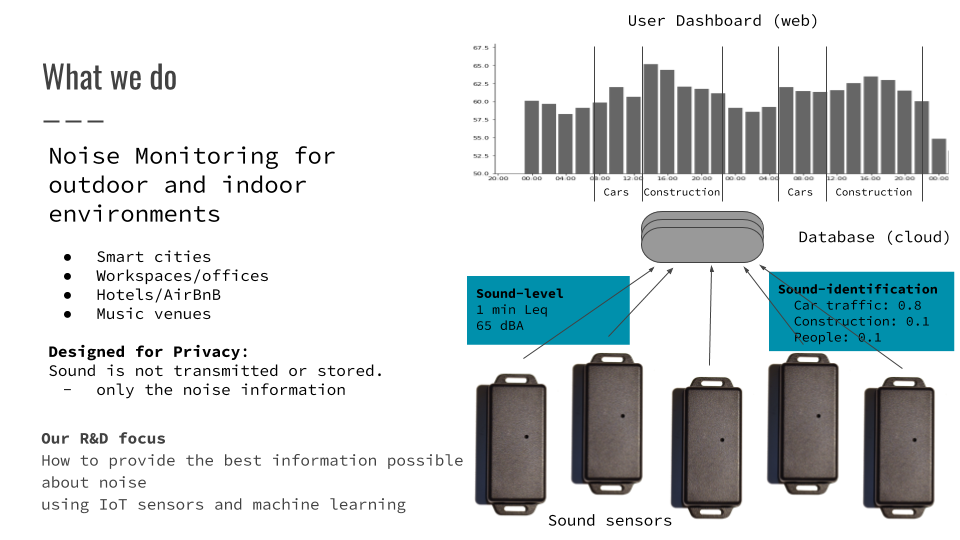
Soundsensing

Dashboard
Thesis
Environmental Sound Classification on Microcontrollers using Convolutional Neural Networks

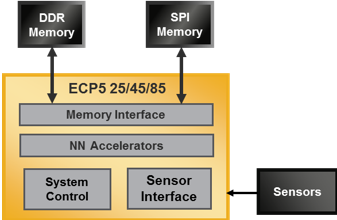
Sensor Network Architectures
General purpose microcontroller
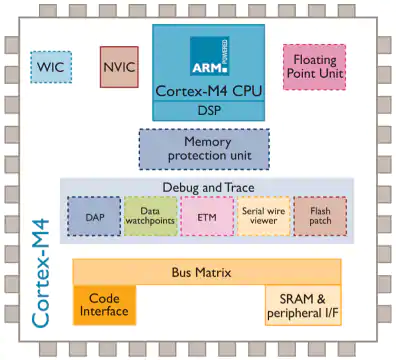
STM32L4 @ 80 MHz. Approx 10 mW.
- TensorFlow Lite for Microcontrollers (Google)
- ST X-CUBE-AI (ST Microelectronics)
FPGA
Human presence detection. VGG8 on 64x64 RGB image, 5 FPS: 7 mW.
Audio ML approx 1 mW
Neural Network co-processors
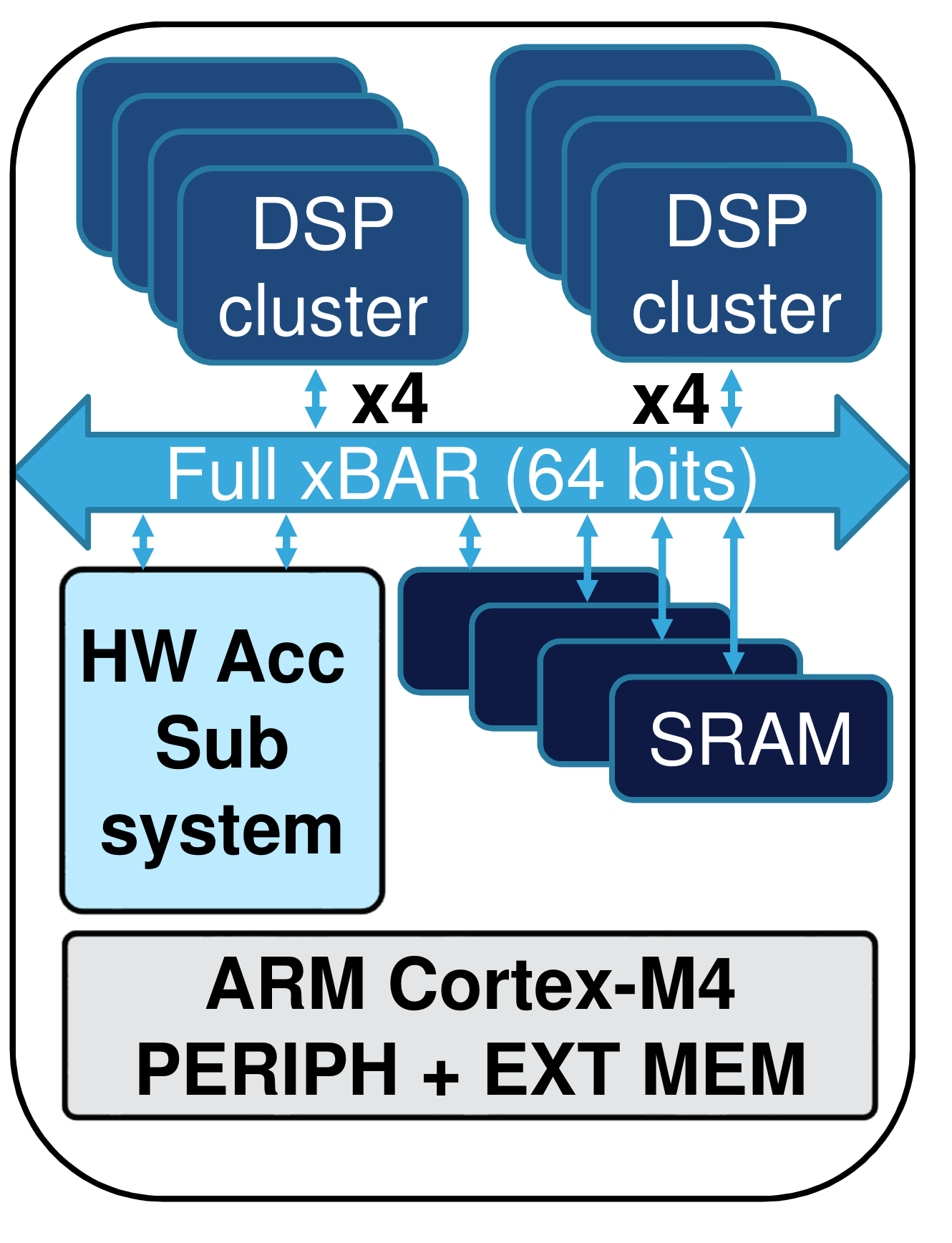
2.9 TOPS/W. AlexNet, 1000 classes, 10 FPS. 41 mWatt
Audio models probably < 1 mWatt.
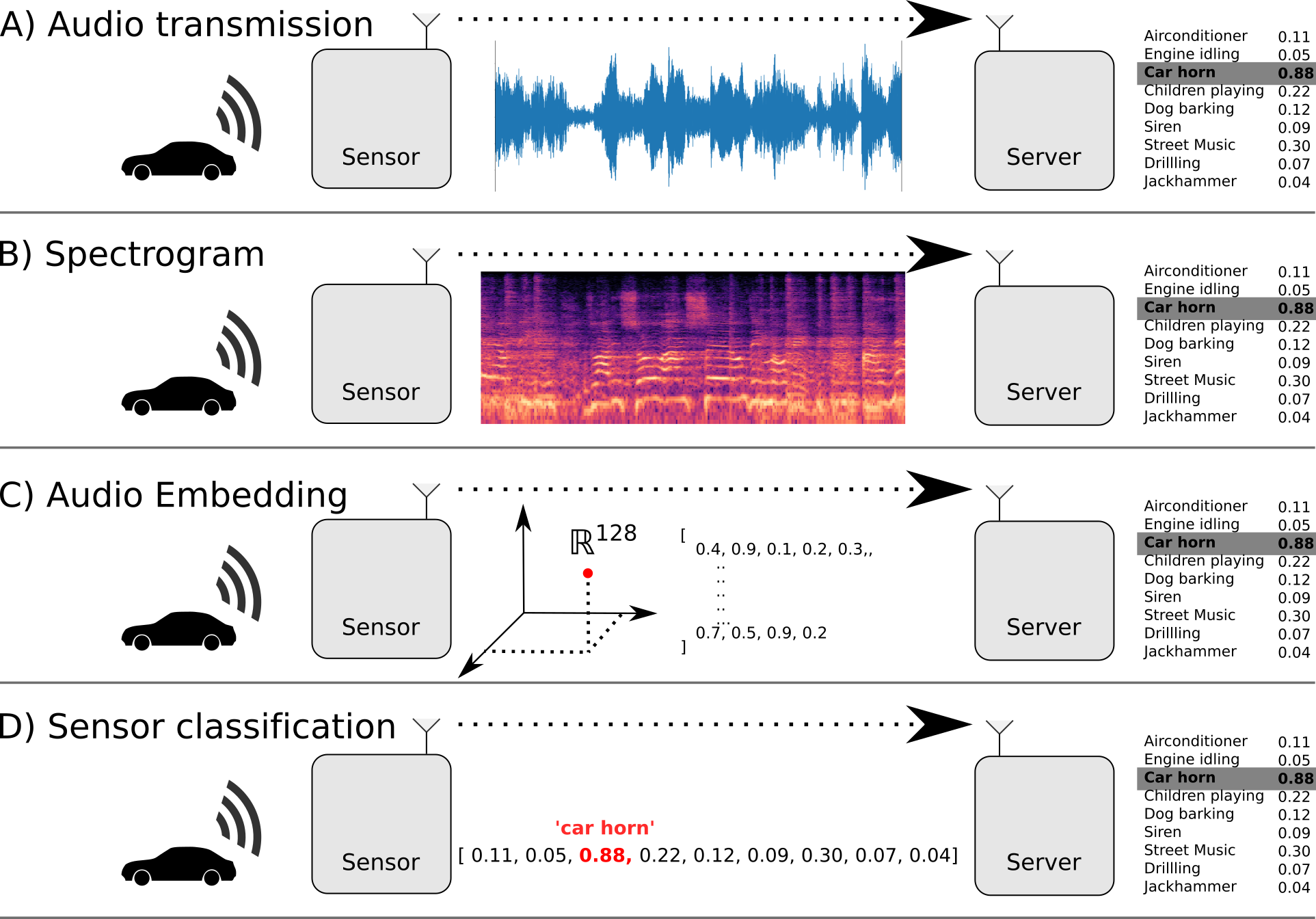
Urbansound8k
Existing models
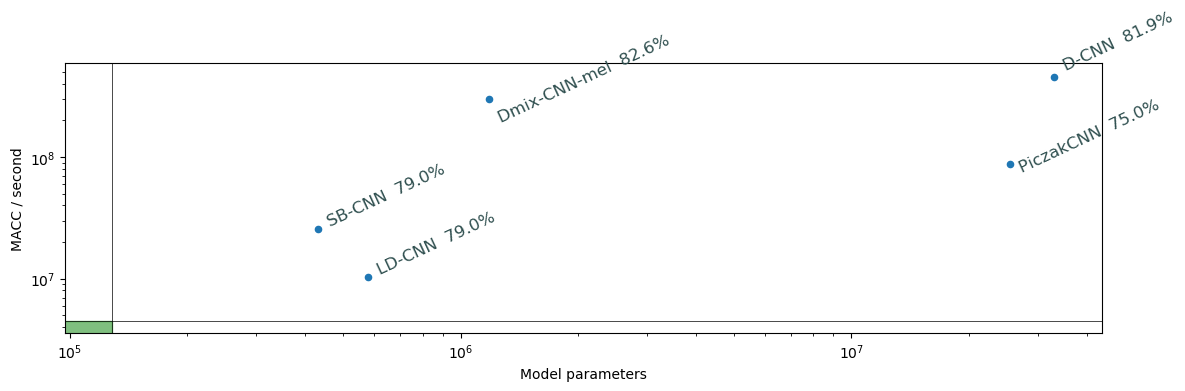
eGRU: running on ARM Cortex-M0 microcontroller, accuracy 61% with non-standard evaluation
Pipeline
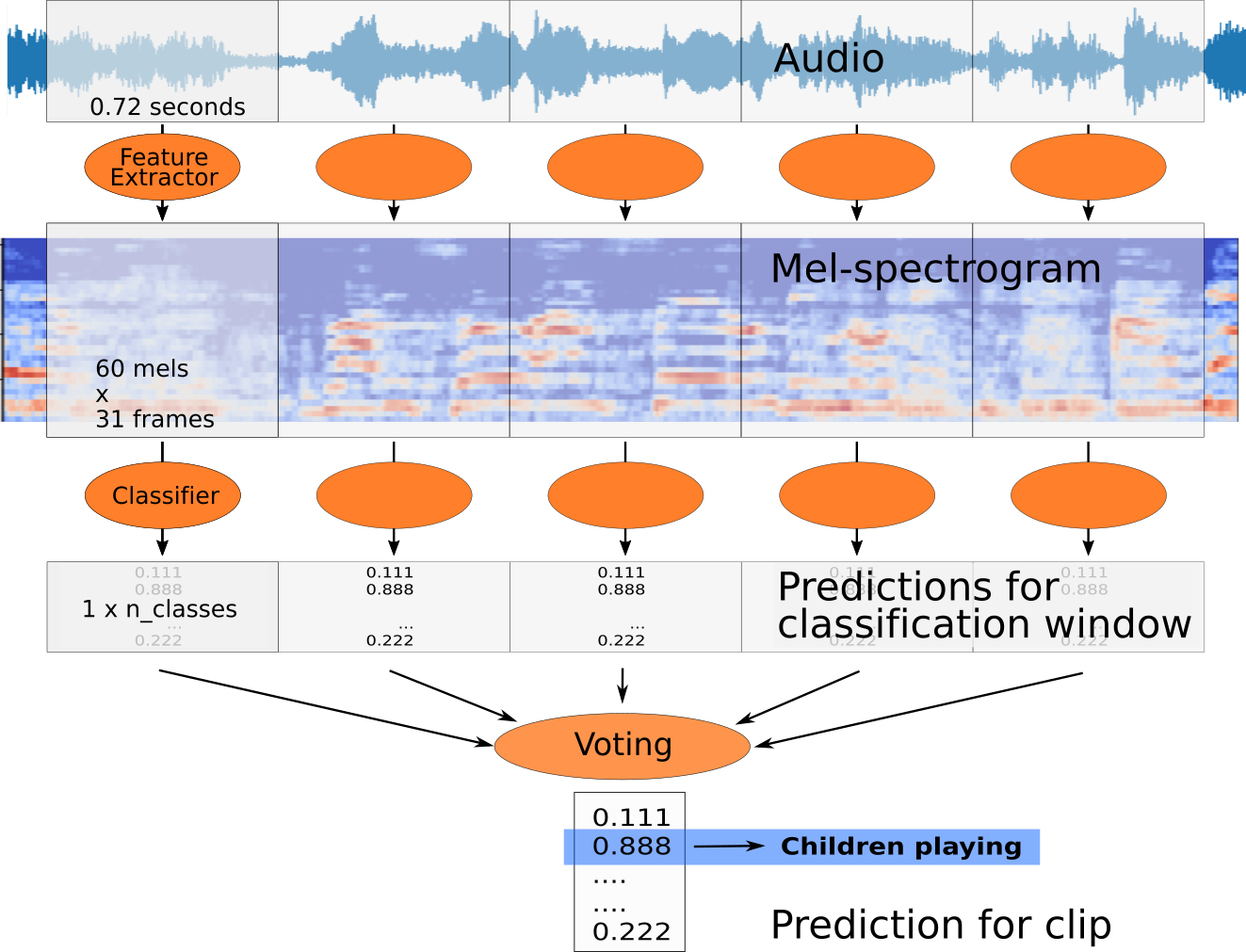
Models

Reduce input dimensionality

- Lower frequency range
- Lower frequency resolution
- Lower time duration in window
- Lower time resolution
Reduce overlap
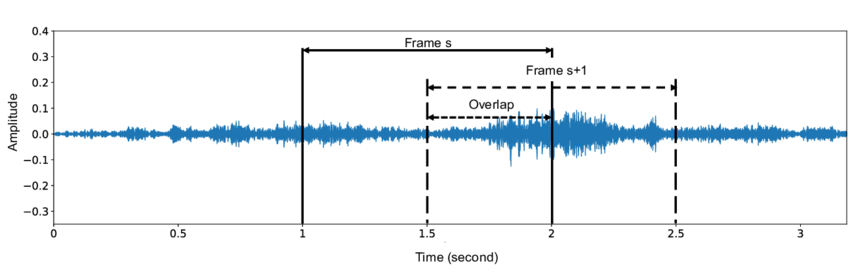
Models in literature use 95% overlap or more. 20x penalty in inference time!
Often low performance benefit. Use 0% (1x) or 50% (2x).
Depthwise-separable Convolution
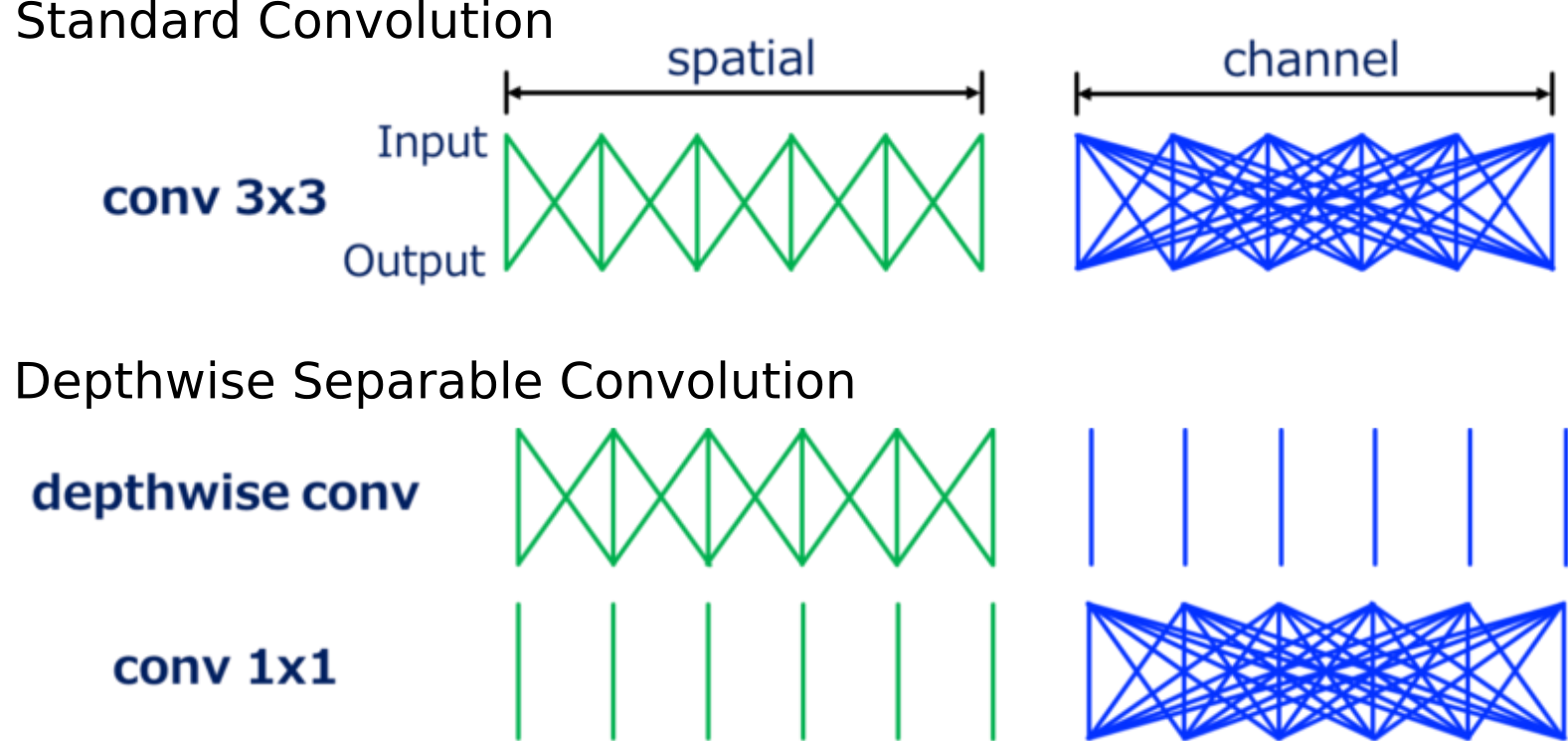
MobileNet, “Hello Edge”, AclNet. 3x3 kernel,64 filters: 7.5x speedup
Spatially-separable Convolution

EffNet, LD-CNN. 5x5 kernel: 2.5x speedup
Downsampling using max-pooling
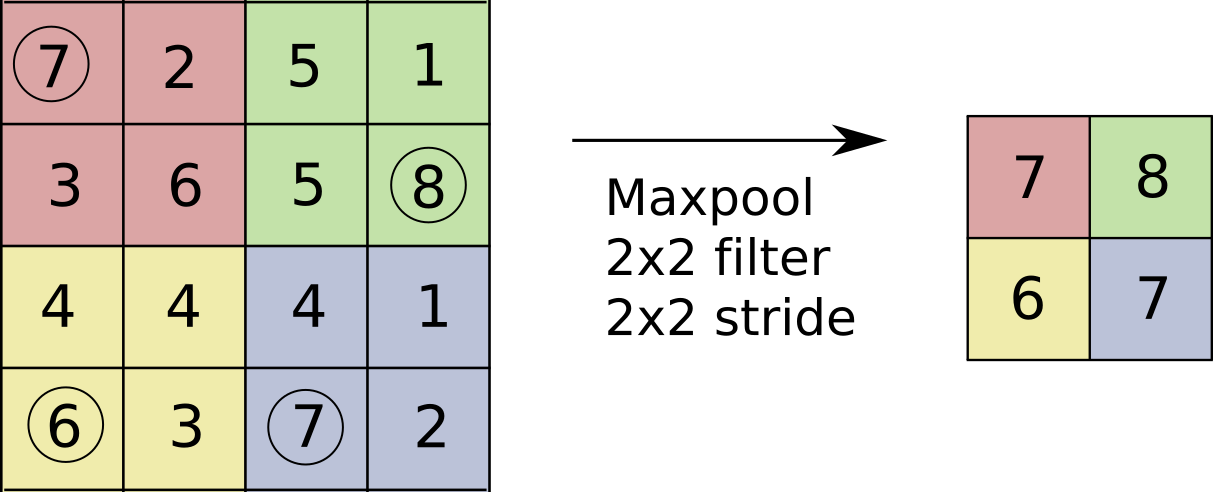
Wasteful? Computing convolutions, then throwing away 3/4 of results!
Downsampling using strided convolution
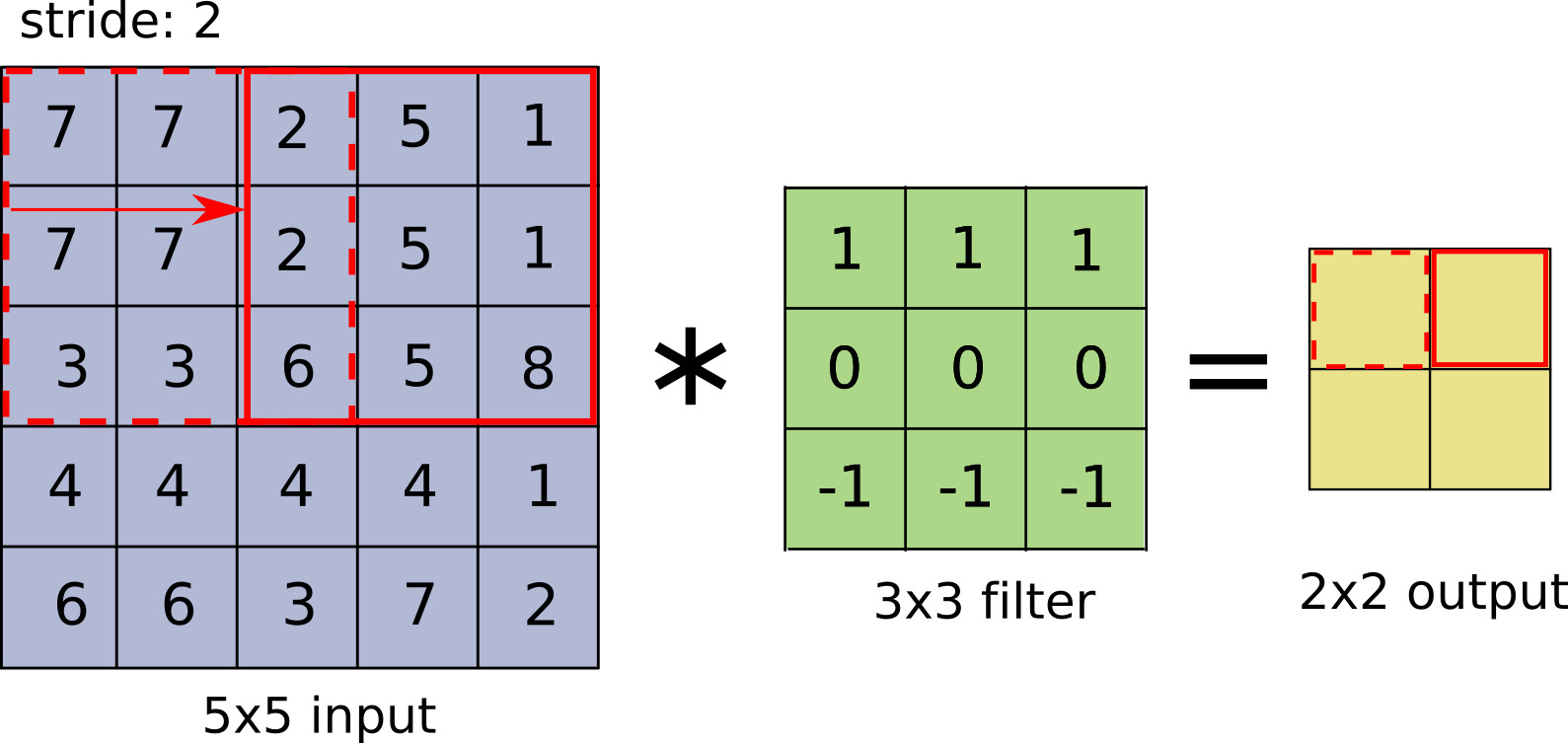
Striding means fewer computations and “learned” downsampling
Model comparison
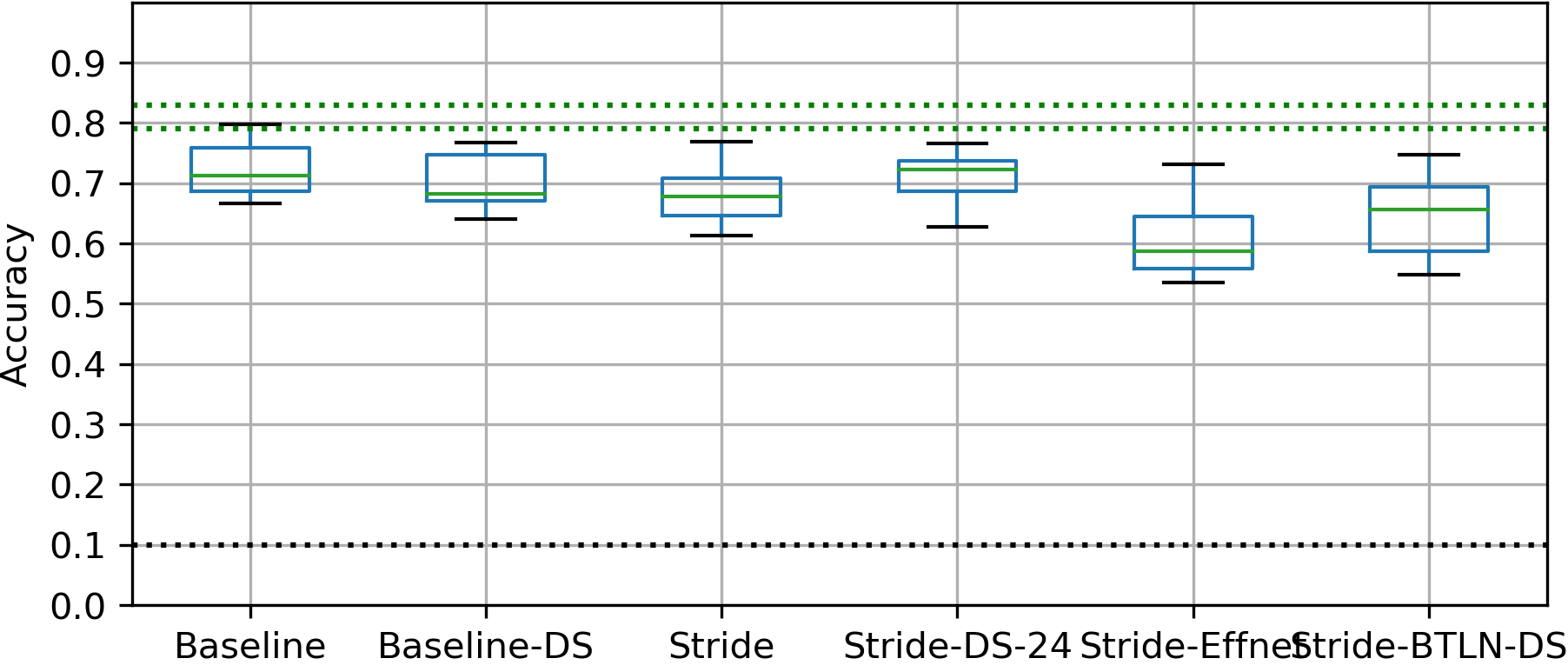
Performance vs compute
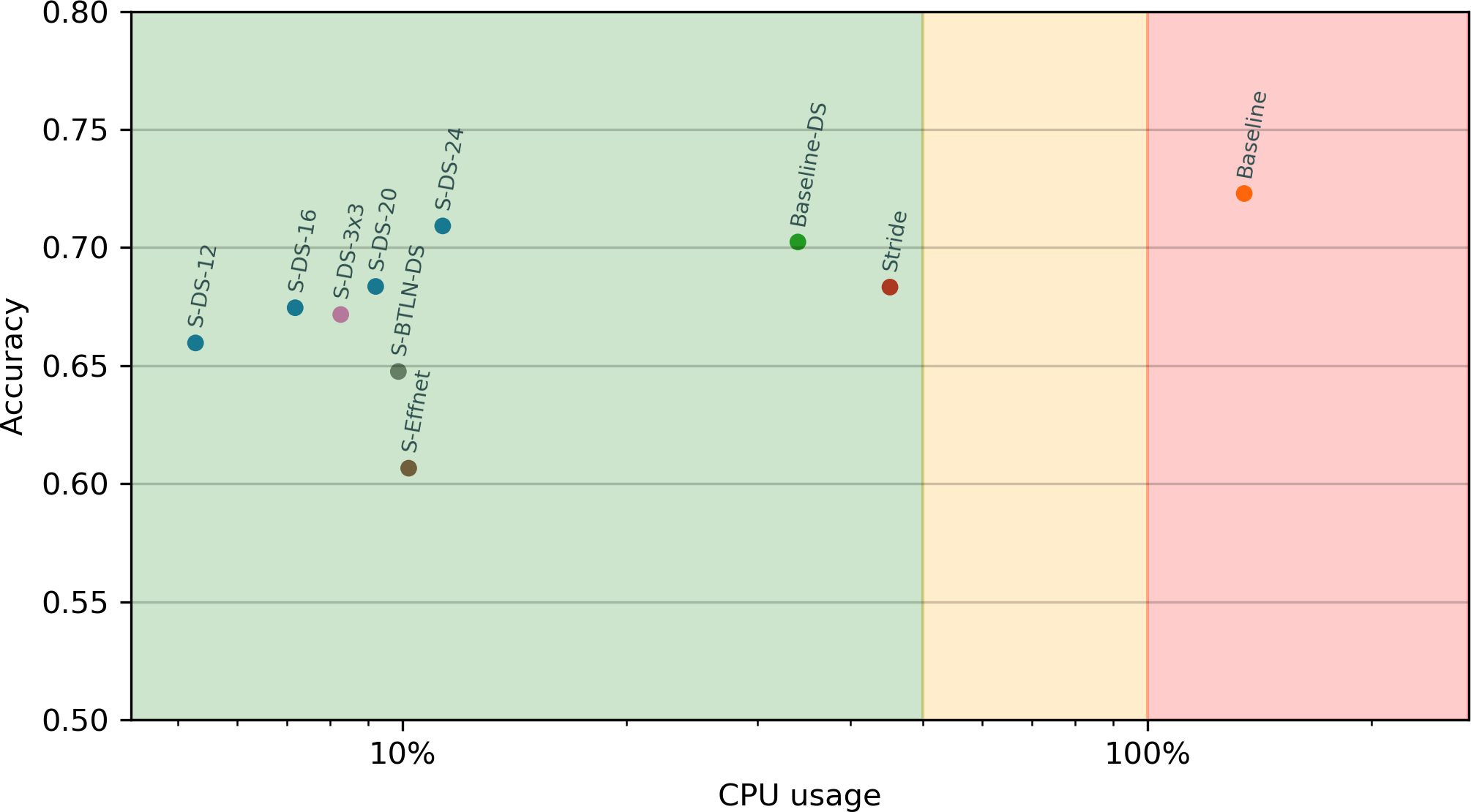
:::
- Performance of Strided-DS-24 similar to Baseline despite 12x the CPU use
- Suprising? Stride alone worse than Strided-DS-24
- Bottleneck and EffNet performed poorly
- Practical speedup not linear with MACC
:::
Model comparison
List of results

Confusion
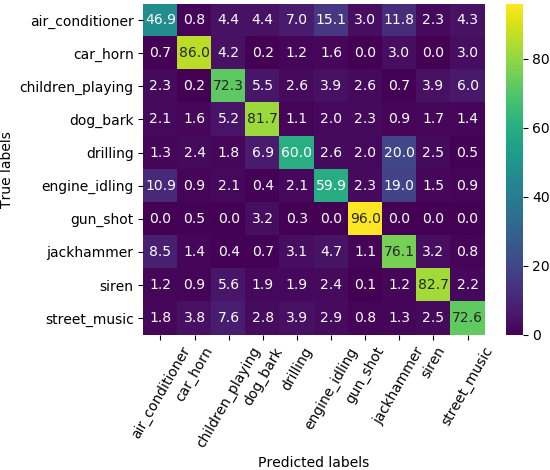
Grouped classification
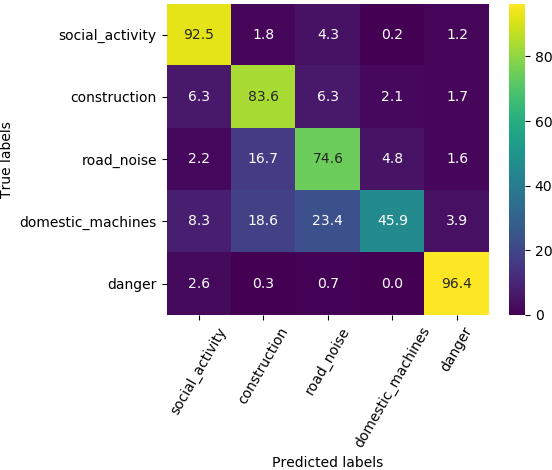
Foreground-only
Unknown class

All models

Training settings

FAIL: Integer truncation

FAIL. Dropout location

Mel-spectrogram

Noise Mapping
Simulation only, no direct measurements